ETL Process Optimization: Faster and Smarter Data Pipelines
Modern businesses depend on data. Every report, dashboard, and prediction starts with moving data from one system to another. This process is called ETL, which stands for Extract, Transform, and Load. When ETL runs slowly or fails often, the whole business feels the impact.
ETL process optimization helps make data pipelines faster, more reliable, and easier to manage. It reduces delays, cuts costs, and improves the quality of data that teams use every day. Because data volumes keep growing, optimization is no longer optional. It is now a core part of every data strategy.
In this guide, you will learn what ETL process optimization means, why it matters, which techniques work best, and how to improve your own pipelines step by step.
What Is ETL Process Optimization?

ETL process optimization is the practice of improving how data is extracted, transformed, and loaded into target systems.
The goal is simple:
- Move data faster
- Reduce system load
- Improve reliability
- Lower processing costs
- Deliver clean data on time
Instead of rewriting everything, optimization focuses on fixing slow steps, removing waste, and choosing better tools or designs.
Why ETL Optimization Matters
Data pipelines run behind almost every business system. Reports, machine learning models, customer analytics, and real-time dashboards all depend on them.
When ETL is slow or unstable:
- Reports arrive late
- Dashboards show outdated numbers
- Systems crash under heavy load
- Teams lose trust in data
In areas like Customer Retention Analytics, fast and accurate ETL is critical. Even small delays can lead to wrong decisions and lost customers.
Optimized ETL pipelines:
- Deliver fresh data faster
- Reduce server and cloud costs
- Improve data quality
- Scale easily as data grows
Key Stages of the ETL Process
Before optimizing, it helps to understand where problems usually happen.
1. Extract Stage
Data comes from databases, APIs, files, or streaming systems. Slow queries, network delays, and poor indexing often cause bottlenecks here.
2. Transform Stage
This is where data gets cleaned, joined, filtered, and enriched. Heavy calculations and poor memory use usually slow this stage.
3. Load Stage
Data moves into data warehouses or lakes. Writing large files, handling duplicates, and managing indexes affect performance.
Each stage offers many chances for optimization.
Common ETL Performance Problems
Many ETL pipelines face the same issues.
Large Data Volumes
As data grows, old pipelines cannot keep up.
Poor Query Design
Slow queries waste time and overload source systems.
Inefficient Transformations
Complex rules and nested joins slow processing.
Limited Hardware Resources
CPU, memory, and disk limits reduce throughput.
Lack of Monitoring
Without visibility, problems stay hidden until failures happen.
ETL Process Optimization Techniques
Now let’s explore the most effective ways to optimize ETL pipelines.
Parallel Processing
Parallel processing splits work into smaller tasks and runs them at the same time.
Instead of loading one table at once, the system loads many tables together. This approach:
- Reduces total run time
- Uses CPU resources better
- Improves scalability
Most modern ETL tools support parallel execution. Turning it on often delivers instant performance gains.
Incremental Data Loading
Full loads waste time and resources. Incremental loading only moves new or changed data.
Benefits include:
- Faster execution
- Lower network usage
- Reduced load on source systems
Change Data Capture (CDC) is a popular method for incremental ETL. It tracks updates in real time and sends only the differences.
Push Transformations to the Database
Instead of transforming data inside the ETL tool, move transformations into the database.
Databases are built for:
- Fast joins
- Efficient filtering
- Large aggregations
This approach reduces data movement and improves overall speed.
Optimize Source Queries
Extraction speed depends on query design.
Best practices include:
- Use indexed columns
- Avoid unnecessary joins
- Select only needed fields
- Filter early in the query
Well-written queries reduce both run time and system stress.
Partition Large Data Sets
Partitioning splits large tables into smaller pieces.
Each partition processes separately, which:
- Improves parallelism
- Reduces memory usage
- Speeds up loading
Partitioning works well for time-based data such as logs, events, and transactions.
Use Staging Tables
Staging tables act as temporary storage between stages.
They help by:
- Isolating transformations
- Reducing locking issues
- Making recovery easier after failures
This design improves reliability and simplifies debugging.
Compression and File Formats
Choosing the right file format matters.
Optimized formats like:
- Parquet
- ORC
- Avro
These reduce storage size and speed up reads and writes.
Compression lowers network traffic and cuts cloud storage costs.
Resource Management and Scheduling
ETL jobs compete with other workloads.
Smart scheduling:
- Runs heavy jobs at off-peak hours
- Avoids overloading production systems
- Balances CPU and memory use
Modern schedulers adjust resources automatically based on job size.
Monitoring and Logging
Optimization never ends without monitoring.
Good monitoring shows:
- Job duration
- Failed records
- Memory usage
- Throughput rates
Early detection prevents small problems from becoming major outages.
This becomes even more important in advanced systems like those used in Digital Twin for Urban Planning, where real-time data accuracy is critical.
Cloud-Based ETL Optimization
Cloud platforms change how ETL works.
Key benefits include:
- Auto-scaling resources
- Pay-as-you-go pricing
- Managed infrastructure
Cloud ETL tools can scale instantly when data spikes happen. This flexibility makes optimization easier and cheaper.
Real-Time and Streaming ETL
Batch ETL works well for reports, but many systems now need real-time data.
Streaming ETL:
- Processes data continuously
- Updates dashboards instantly
- Supports event-driven systems
This model fits well with IoT and smart systems such as those described in Internet of Things (IoT) Protocols.
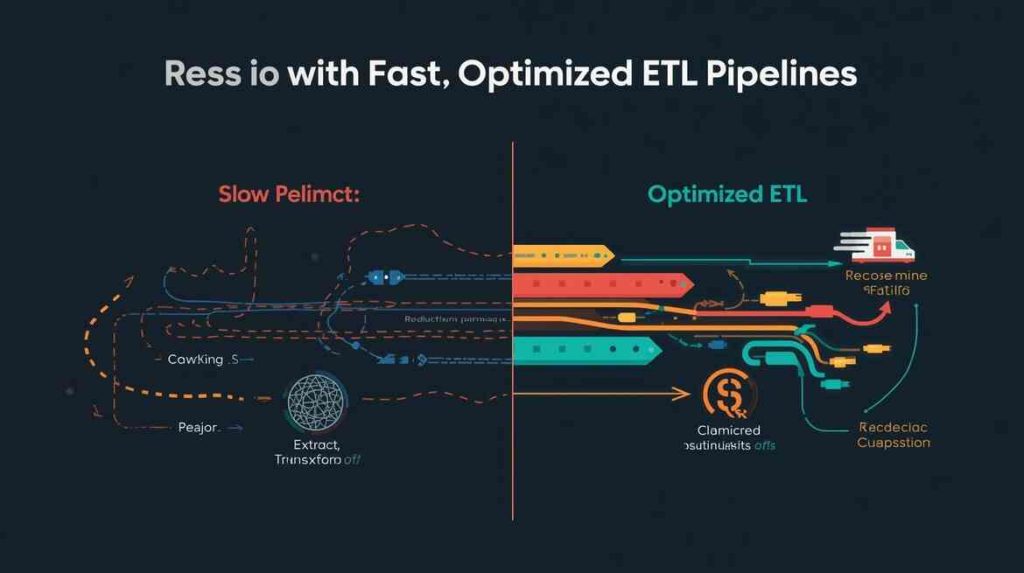
Comparing Traditional vs Optimized ETL
| Feature | Traditional ETL | Optimized ETL |
|---|---|---|
| Speed | Slow batch jobs | Fast parallel loads |
| Scalability | Limited | High and flexible |
| Resource use | Heavy | Efficient |
| Data freshness | Delayed | Near real-time |
| Reliability | Lower | Much higher |
Optimized pipelines clearly outperform older designs in every area.
Best Practices for Long-Term Optimization
To keep ETL pipelines healthy:
- Review performance regularly
- Update indexes and partitions
- Remove unused transformations
- Test with realistic data volumes
- Document pipeline logic clearly
Small improvements added over time produce major gains.
Final Thoughts
ETL process optimization is essential in modern data systems. As data volumes grow and business decisions depend more on real-time insights, slow pipelines become a serious risk.
By using parallel processing, incremental loading, query optimization, smart scheduling, and monitoring, you can build fast and reliable ETL pipelines that scale with your business.
Well-optimized ETL does more than move data. It builds trust, improves decisions, and supports long-term growth.
FAQs
It is the practice of improving ETL speed, reliability, and efficiency.
It reduces delays, lowers costs, and improves data quality.
Incremental loading and parallel processing deliver the fastest results.
Yes, cloud tools provide auto-scaling and flexible resource control.